
If we want machines to think, we need to teach them to see
Fei-Fei Li
Computer vision is one of the most challenging and fascinating field of machine learning. We can say it acquired popularity back in 2010 since the ILSVRC (Large Scale Visual Recognition Challenge) competition was introduced by Alex Berg from Stony Brook, Jia Deng from Princeton & Stanford, and Fei-Fei Li from Stanford. It consisted in a classification task on the huge image database ImageNet which provided more than 1,000,000 labeled training images and 100,000 test images where the competitors had to output the top 5 (out of 1,000) most likely categories for each picture. Just to give an idea about the difficulty of this task, can you distinguish whether the following pictures depict a chihuahua or a muffin?

Actually, this is a very challenging task even for a human, they look so similar. No wonder why fully connected networks and traditional machine learning models never showed acceptable results in this task. It’s only thanks to an amazing breakthrough in the deep learning field that machines not only achieved excellent results, but even outperformed humans in image classification tasks.
Convolutional neural networks (CNN), also known as shift invariant or space invariant artificial neural network, are a specialized kind of feed-forward neural networks where the standard matrix multiplication operation across the value of its neurons is replaced by convolution. Those kind of networks resemble the activity of the brain’s visual cortex and the connectivity patterns among its neurons. They have been invented by the “Turing Triangle”: Geoffrey Hinton, Yann LeCun and Yoshua Bengio but had been studied since 1980. Only thanks to the increase in computational power and the amount of available training data they acquired popularity in the deep learning field such that nowadays, convolutional layers can be found in most of the machine learning models. They are suitable for wide applications in image and video recognition, classification and generation, self-driving cars, recommendation systems and natural language processing.
Why convolutional neural networks?
Imagine we have to feed a newtork with an image of resolution 200x200x3 where the first two terms denote its size and the last term indicates the number of channels (RGB). An input fully connected layer would require up to 200x200x3=120,000 units to get the whole image. Moreover, in deep feed-forward networks each hidden layer is fully connected to all neurons in the previous layer. For example, a second layer of 1000 neurons connected directly to the input would require a total of 120000×1000=120,000,000 connections and so on for the following layers! A network with millions of parameters not only would be terribly slow during training, but it would also be more prone to be subject to overfitting. Thus, we can affirm that fully connected networks do not scale well to higher resolution images due to the structure of their fully connected layers.

Unlike a regular neural network, the layers of a convolutional network (convolutional layers) have neurons arranged in three dimensions: width, height and depth. In this way, every layer of a CNN transforms the 3D input volume into a 3D output volume through a differentiable learnable function.

What makes them useful is that neurons in a convolutional layer are not connected to every single neuron of the previous layer, but only to some specific neurons inside their receptive field. In fact, each neuron in the first convolutional layer is not connected to each pixel of the input image, but only to the pixels located in a smaller area (receptive field).

Suppose that the input volume has size 32x32x3. If the receptive field (or the filter size) is 5×5, then each neuron in the convolutional layer will have connections to a 5x5x3 region in the input volume for a total of just 75 weights. Thus, the connectivity is local in space (5×5), but full along the input depth (3).
Because of this particular structure we have that the lower layers focus on extracting lower-level features from the input image such as edges or corners, while higher level layers compose these basic features to extract higher-level structures such as eyes or mouths and so on. Layer by layer, different-level features are assembled in a hierarchical way until the whole image gets recognized. This hierarchical structure is also very common in real-world images.

Convolutional layers
When working with images, we usually think of the input I and output Z of convolution as being 3D matrices where the first dimension is the number of channels (1 for gray-scale images, 3 for RGB images…).
In machine learning the operation of convolution is defined as follow:
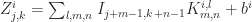
Where Zj,ki is the value of output unit within channel i at row j and column k. The kernel K is a 4D matrix with element Km,ni,l representing the connection strength between an output unit in channel i and an input unit in channel l at row m and column n. bi is a bias term for each output channel i.
One of the most interesting proprieties of the convolution is that the operation is shift invariant, which means that the value of the output depends on the pattern in the image neighborhood, but not on the position of the neighborhood.
We may also skip over some positions of the kernel in order to reduce the computational cost, thus downsampling the input image:
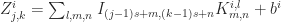
Where s is the stride and denotes the distance between two consecutive receptive fields, that is, how many pixels skipping left and right before performing the next convolution. When the stride is 1, then we move the kernels one grid at a time. When the stride is 2, then the kernels jump 2 grids at a time and so on. This will produce smaller output volumes.

Sometimes it will be convenient to pad the input volume with zeros around the border. The nice feature of zero-padding is that it will allow us to control the spatial size of the output volumes (one special case is when enough zero-padding is added to keep the size of the output equal to the size of the input). In this way, can be performed the convolution even on those pixels close to the edge whose receptive field would partially lay outside the original volume.

The third hyperparameter that controls the size of the output volume is the depth, which corresponds to the number of kernels or feature maps i we would like to use. In fact, a convolutional layer is composed of several feature maps of equal sizes where neurons in the same feature map share the same parameters, while different feature maps may have different parameters. That is, the neurons in the same feature map detect the same patterns but in different spatial locations in the same layer. A neuron’s receptive field doesn’t have a scope on a single feature map but extends across all the feature maps of the previous layer. In short, a convolutional layer simultaneously applies multiple filters to its inputs, making it capable of detecting multiple features anywhere in its inputs. Hence, a convolutional layer takes in input a 3D matrix of depth l and outputs a 3D matrix of depth i.

Convolutional kernerls
We mentioned before that a kernel K, is a function of the input I, but what is its purpose? Each feature maps of a convolutional kernel Ki,l learns a filter, which is a function that defines how to combine values from neighbors pixels with the goal of detecting particular patterns inside the receptive field area. As an example, let’s say that we have a filter of 5×5 size full of 0s except for the central column, which is full of 1s. Neurons using these weights will ignore everything in their receptive field except for the central vertical line (since all inputs will get multiplied by 0, except for the ones located in the central vertical line). Now if all neurons in a layer use the same vertical line filter and we feed the network the input image, we will have that the vertical lines get enhanced while the rest gets blurred. Actually, the Deep Dreaming algorithm exploits this technique to enhance the patterns found by the filters of a layer and gradually draw them on the original input image. Anyway, we don’t have to define those filters manually, but during training, a CNN learns the most useful filters for its task and how to combine them into more complex patterns.

Training a convolutional layer
Convolutional layers, as well as fully connected layers, are trained using backpropagation. The goal is to minimize a loss function J(K,b), where K is the 4D kernel matrix containing the filters and b is the bias vector. Using the chain rule, the derivatives with respect to the kernel can be written as:


Thus, the parameters Km,ni,l and bi can be updated as follows:

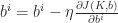
Pooling layers
Another new type of layer present in a CNN is the pooling layer. This layer has the task of downsampling or shrinking the input image. This is helpful not only to save memory or reduce the computational cost, but also to limit the numbers of parameters of the network, thus, reducing the risk of overfitting. Furthermore, reducing the input image size also makes the neural network more location invariant, which means that it can better tolerate small translations of the input. Like in convolutional layers, each neuron in a pooling layer is connected to the output neurons in the previous layer located inside a rectangular fixed area. Hence, its parameters are the size of the receptive field, the stride and the padding type, but it has no weights. What it does is applying a pooling function that replaces the output of the previous layer at a certain location with a summary statistic of the nearby output. Some of these pooling functions include:
- Max pooling
- Average pooling
- L2-norm pooling
- Probability weighted pooling
For example, the max pooling functions returns the pixel with the highest value inside the receptive field, while average pooling returns the mean of the inputs.

The backpropagation of a pooling layer is just an upsampling operation that inverses the subsampling in the forward pass. For example, the backward pass for a max pooling layer routes the gradient to the input that had the highest value in the forward pass.

CNN architecture
A typical CNN is composed by three kind of layers:
- Convolutional layers
- Pooling layers
- Fully connected layers
A convolutional neural network usually stacks some convolutional layers at the beginning to get the input image, then a pooling layer to downsample it and then it keeps mixing convolutional and pooling layers in order to extract and compose more complex features. Hence, the image gets smaller as it progresses through the layers of the network and also gets deeper thanks to the convolutional layers adding more features map to it. Finally, some regular few fully connected layers are stacked at the top of the network in order to classify the input class, and a final output layer is used to output the prediction (usually it’s a softmax layer if we want to estimate class probabilities).

References
- https://thudm.github.io/Tsinghua-ML-Course/slides/9-CNN.pdf
- https://www.oreilly.com/library/view/hands-on-machine-learning/9781492032632/
